
지난번 포스팅에 이어 인프런에 있는 데브원영님의 [아파치 카프카 애플리케이션 프로그래밍] 개념부터 컨슈머, 프로듀서, 커넥트, 스트림즈까지! 학습한 내용을 간단하게 정리해 두고자 포스팅을 합니다.
지난번 포스팅은 아래 링크 참고 부탁드립니다.
카프카 클러스터를 운영하는 방법
- 서버에 직접 설치 운영
- 각종 설정을 직접 컨트롤
- 수많은 시행착오
- 각종 설정을 직접 컨트롤
- 운영 방법에 따른 서비스 형태
- SaaS SW 와 infra 를 관리하여 제공
- 웹 대시보드나 CLI 를 통해 플랫폼의 세부 설정을 간편하게 설정
- SaaS SW 와 infra 를 관리하여 제공
SaaS 형 Kafka 소개
- 클라우드 서비스 - Confluent
- connector, ksqlDB (sql 을 통해 producing - filtering, join, transform), rest proxy
- 컨플루언트 클라우드
- 120개가 넘는 커넥터, ksqlDB, 스카마 레지스트리 제공
- 데이터 적재 제한 없음
- 컨플루언트 플랫폼
- on-premiss 설치
- 단계별 스토리지 기능 (tiered-storage) 제공
- GUI 기반 모니터링 시스템 제공
- 클라우드 서비스 - AWS MSK
- 오픈소스 설치, 추가 모니터링
- TLS 인증 보안 설정
- apache kafka 버전 선택 가능
SaaS 형 아파치 카프카 장점과 단점
- 인프라 관리의 효율화
- 카프카 클러스터는 최소 3대 이상 서버로 운영
- 모니터링 대시보드 제공
- 보안 설정
- SSl, SASL, ACL 설정
- 서비스 사용 비용
- 커스터마이징 제한
- 최적화 옵션 또는 브로커 옵션 x
- multi cloud 또는 hybrid cloud 불가
- 클라우드의 종속성
- 운영 노하우가 부족한 상태에서 빠르게 구축시 효과적
카프카 커멘드 라인툴
- 선택 옵션 : 지정하지 않을 시 브로커에 설정된 기본값 또는 커맨드 라인 툴의 기본값으로 대체되어 설정
로컬 카프카 설치 및 실행
- 카프카 바이너리 압축 해제
- bin - 실행 파일
- config - 설정 파일
- libs - 실행에 필요한 Library
- data - 데이터가 쌓일 디렉토리
- server.properties (브로커)
- log.dirs - 데이터 저장되는 디렉토리
- num.partitions - 토픽 생성시 기본 파티션 개수
- log.retention.hour - 해당 시간 만큼 보관 후 삭제 (df. 168)
- log.segment.bytes - segment 파일 단위
- log.retention.check.interval - retention check 주기
- broker.id - 0부터 1씩 늘려간다
- zookeeper -> kafka (broker) 순으로 실행
- kafka-broker-api-version.sh - 내부 option 값 확인
- kafka-topics.sh - 토픽 리스트 확인
kafka-topics.sh
- 클러스터 정보와 토픽이름은 토픽을 만들기 위한 필수값
- –create –topic {토픽명} 옵션으로 생성
- –describe : 파티션 개수, 복제 개수, 파티션, leader, replicas, ISR 등 확인 가능
- –alter : 파티션 개수를 늘릴 수 있다
kafka-configs.sh
- 토픽의 일부 옵션을 설정
- server.properties 에 설정된 각종 기본값을 조회할 수 있다.
- –broker, –all, –describe 옵션
kafka-console-producer.sh
- 메시지 키를 가지고 레코드 전송 : parse.key=true
- key.separator 를 선언하지 않으면 기본 설정은 Tab delimiter
- 동일한 메시지 키는 동일한 한개의 파티션으로 전송
순서 보장 가능
kafka-console-consumer.sh
- 메시지 키와 값을 확인하고 싶다면 –property 옵션을 사용
- –from-beginning 옵션 - 처음부터 읽는다.
- –max-messages 옵션 - 최대 컨슘 메시지 개수를 설정
- –partition 옵션 - 특정 파티션만 컨슘할 수 있다.
- –group 옵션 - 특정 목적을 가진 컨슈머들은 묶음으로 사용하는 것을 뜻한다.
- 토픽의 레코드를 가져가면 커밋을 통해 어느 레코드까지 읽었는지 브로커에 저장
- –group 미지정시 임시 그룹이 생성되나, 일정시간 후 자동삭제
kafka-consumer-groups.sh
- 컨슈머 그룹을 관리
- –describe 옵션으로 어떤 토픽을 대상으로 레코드를 가져갔는지 상태확인 가능
- 파티션 번호, 현재까지 가져간 레코드의 오프셋, 파티션 마지막 레코드의 오프셋, 컨슈머 랙, 컨슈머 ID, Host
- –reset-offsets
- –to-earliest - 가장 처음 오프셋으로 리셋
- –to-latest - 가장 마지막 오프셋으로 리셋
- –to-current - 현 시점 기준 오프셋으로 리셋
- –to-datetime {YYYY-MM-DDTHH:MM:SS.sss} - 레코드 타임스탬프 기준 특정 일시로 리셋
- –to-offset {long} - 특정 오프셋으로 리셋
- –shift-by {+/- long} - 현재 컨슈머 오프셋 앞뒤로 옮겨서 리셋
- inactive group 에만 적용 가능
kafka-producer-perf-test.sh, kafka-consumer-perf-test.sh
- 퍼포먼스를 측정할 떄 사용
kafka-reassign-partitions.sh
- 리더 파티션이 특정 브로커로 쏠림 (hot spot 현상) 발생시 사용
- auto.leader.rebalance.enable 옵션 - 클러스터 단위에서 자동 리밸런싱 (df. true)
- 리더 파티션이 알맞게 분배되는게 중요
kafka-delete-record.sh
- 특정 토픽, 파티션, 오프셋 (이전 데이터 모두)
kafka-dump-log.sh
- 이슈 확인용
토픽을 생성하는 두가지 방법
- 컨슈머, 프로듀서가 브로커에 생성되지 않는 토픽에 데이터를 요청할 때
- 기본설정에 따라 생성
- 툴을 통한 명시적으로 생성
카프카 브로커와 로컬 CLI 툴 버전을 맞춰야 하는 이유
- 버전 차이로 인해 명령이 정상적으로 실행되지 않을 수 있다.
프로듀서
- 데이터의 시작점
- 카프카에 필요한 데이터를 선언하고 브로커의 특정 토픽의 파티션(리더파티션)에 전송
- 파티셔너, 배치 생성 단계를 내부적으로 가진다.
프로듀서 내부 구조
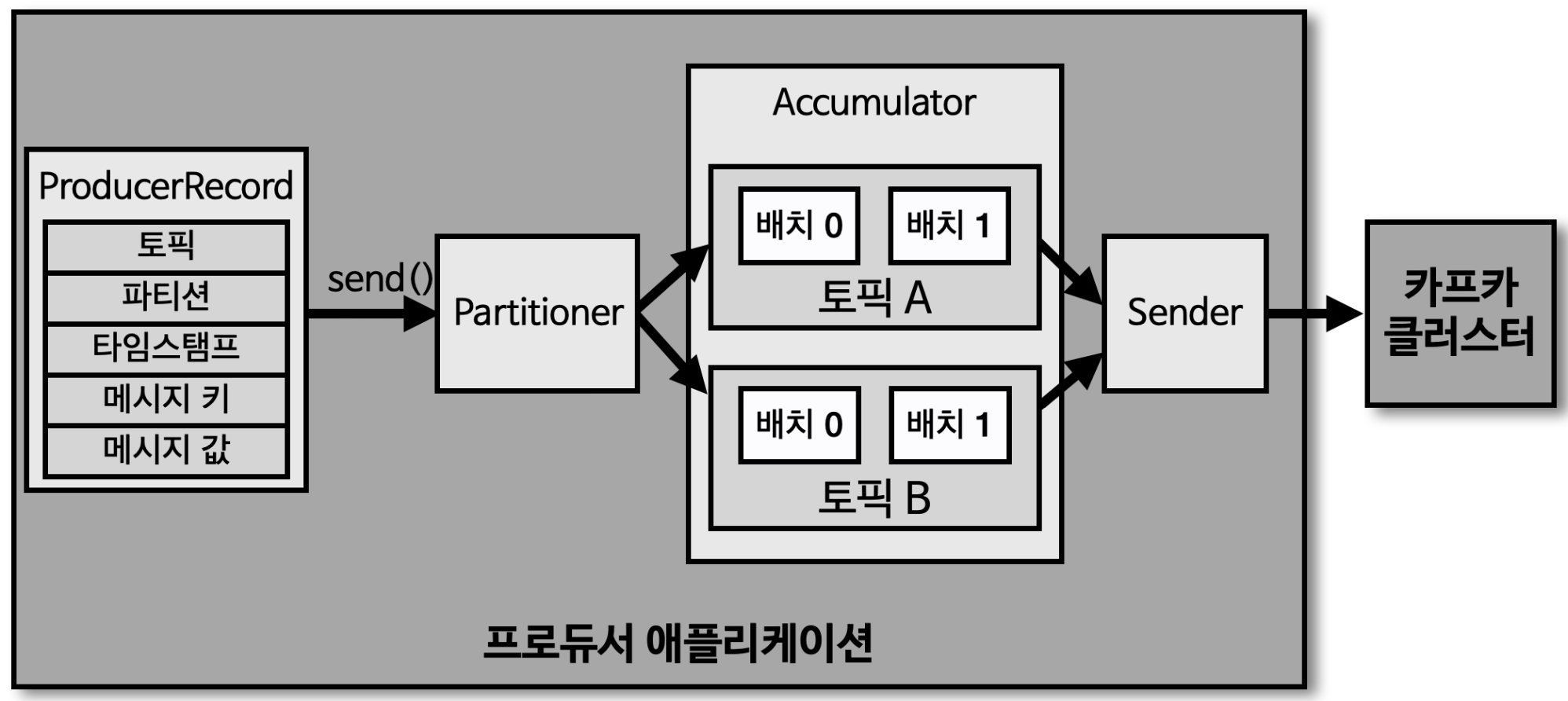
- ProducerRecord : 프로듀서에서 생성하는 레코드, 오프셋은 비포함
- 토픽, 파티션, 타임스탬프, 메시지 키, 메시지 값
- send() : 레코드를 전송 요청 메소드
- Partitioner : 어느 파티션으로 전송할지 지정하는 파티셔너
- 메시지 키에 따라 파티셔너가 동작
- Accumulator : 배치로 묶어 전송할 데이터를 모으는 버퍼
- 높은 데이터 처리량 가능
- Sender : 카프카 클러스터와 통신
프로듀서의 기본 파티셔너
- UniformStickyPartitioner : 기본 설정되는 파티셔너
- 메시지 키가 있을 경우
- UniformStickyPartitioner, RoundRobinPartitioner 둘다 메시지 키의 해시값과 파티션을 매칭하여 레코드를 전송
동일한 메시지 키가 존재하는 레코드는 동일한 파티션 번호에 전달됨- 파티션 수가 변동될 경우 메시지 키와 파티션 번호 매칭은 깨지게 됨
- 메시지 키가 없을 경우
- UniformStickyPartitioner 는 RoundRobinPartitioner 의 단점을 개선
- RoundRobinPartitioner
- ProducerRecord 가 들어오는 대로 파티션을 순회하면서 전송
- Accumulator 에서 묶이는 정도가 적기 때문에 전송 성능이 낮음
- UniformStickyPartitioner
- Accumulator 에서 레코드들이 배치로 묶일때 까지 기다렸다가 전송
- 커스텀 파티셔너
- Partitioner 인터페이스를 제공
- 메시지 키 또는 메시지 값에 따른 파티션 지정 로직을 적용할 수도 있다.
프로듀서 주요 옵션 (필수 옵션)
- bootstrap.servers : 브로커의 host:port 를 1개 이상 작성
- key.serializer : 레코드 메시지 키를 직렬화하는 클래스 지정
- value.serializer : 레코드 메시지 값을 직렬화하는 클래스 지정
- string serializer 미사용시 이슈
- kafka-console-consumer 미사용 가능성 (byte[] 사용)
프로듀서 주요 옵션 (선택 옵션)
- acks : 브로커들에 정상적으로 저장되었는지 전송 성공 여부를 확인 (df.1 - 리더파티션 전송 성공 여부 체크)
- linger.ms : 배치를 전송하기 전까지 기다리는 최소 시간 (df.0)
- retires : 브로커로 부터 에러를 받고 난 뒤 재전송 시도 횟수 (df.2147483647)
- max.in.flight.requests.per.connection : 한 번에 요청하는 최대 커낵션 개수 (설정된 만큼 동시에 전송) (df. 5)
- partitioner.class : 파티셔너 클래스를 지정
- enable.idempotence : 멱등성 프로듀서로 동작할지 여부를 설정 (df.false)
- transaction.id : 프로듀서가 레코드를 전송할 때 레코드를 트랜잭션 단위로 묶을지 여부 설정
ISR(In-Sync-Replicas)
- 리더 파티션과 팔로워 파티션이 모두 싱크가 된 상태(오프셋이 동일)
- 팔로워 파티션이 복제하는 시간차 때문에 오프셋 차이가 발생
acks
- 0, 1, all(-1) 값을 가질 수 있다. 신뢰성 높게 지정할 수 있다. or 성능
- acks = 0
- 프로듀서가 리더 파티션으로 데이터 전송 후 저장여부 확인하지 않음(응답 값을 받지 않음)
- 속도는 빠르나, 신뢰도는 낮음
- acks = 1
- 리더 파티션에만 정상 적재되었는지 확인 (응답 값 수신)
- 신뢰도가 높음 (데이터 유실 가능성 존재)
- 가장 일반적인 옵션
- acks = -1(all)
- 리더 파티션과 팔로워 파티션에 모두 정상적으로 적재되었는지 확인
- 속도는 낮으나, 신뢰도는 높음
토픽 단위 설정 가능한 min.insync.replicas 옵션값에 따라 안정성이 달라진다.- ISR 중 최소 1개 이상의 파티션에 데이터가 적재되었음을 확인
- acks = -1 사용시 min.insync.replicas = 2 이상으로 설정
컨슈머
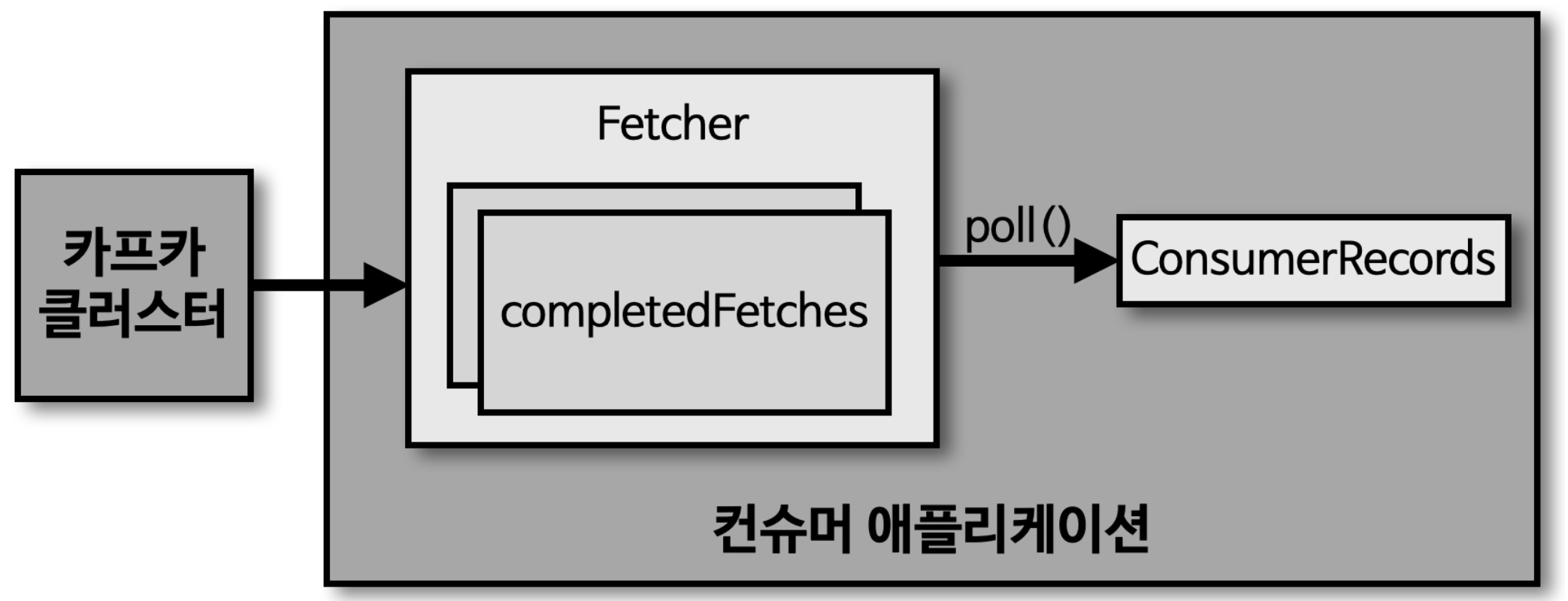
- 브로커에 적재된 데이터를 가져와서 필요한 처리를 함
- Fetcher : 리더 파티션으로부터 레코드를 미리 가져와서 대기
- poll() : Fetcher 에 있는 레코드들을 리턴
- ConsumerRecords : 처리하고자 하는 레코드들의 모음
컨슈머 그룹
- 특정 토픽에 대해 목적에 따라 컨슈머들을 묶은 그룹
- 동일한 로직을 가지는 컨슈머들의 집합
- 각 컨슈머 그룹으로부터 묶인
컨슈머들은 토픽의 1개 이상의 파티션들에게 할당1개의 파티션은 최대 1개의 동일 컨슈머 그룹내 컨슈머에 할당 가능
- 컨슈머 그룹의 컨슈머 개수는 토픽의 파티션 개수와 같거나 작아야 한다.
컨슈머 그룹의 컨슈머 > 파티션 개수
- 파티션을 할당 받지 못하는 유휴 상태로 남는다.
컨슈머 그룹을 활용하는 이유
- 어플리케이션간 강한 커플링을 유용하게 바꿀 수 있다.
- 동일 데이터를 2가지 저장소에 저장할 때 카프카와 컨슈머 그룹을 이용하여 각 저장소의 장애에 격리되어 운영할 수 있다.
리밸런싱
- 토픽과 컨슈머의 할당 과정이 변경되는 과정
- 컨슈머가 추가되는 상황, 제외되는 상황에 발생
- 리밸런싱 리스너로 해당 사황시 처리를 할 수 있다.
- 파티션 개수에 따라 리밸런싱 시간이 증가됨
- 장애와 가까운 상황
커밋
- 컨슈머가 특정 파티션으로부터 데이터를 어디까지 가져갔는지 기록
- 오프셋 커밋이 기록되지 않으면 데이터 처리의 중복이 발생 가능
- 컨슈머가 오프셋 커밋이 정상적으로 처리했는지 검증해야만 한다.
Assigner
- 컨슈머와 파티션 할당 정책은 컨슈머의 Assigner 에 의해 결정
RangeAssigner: 각 토픽에서 파티션을 숫자로 정렬, 컨슈머를 사전 순서로 정렬하여 할당- RoundRobinAssigner : 모든 파티션을 컨슈머에서 번갈아가면서 할당
- StickyAssigner : 최대한 파티션을 균등하게 배분하면서 할당
컨슈머 주요 옵션 (필수 옵션)
- bootstrap.servers : 브로커의 host:port 를 1개 이상 작성
- key.deserializer : 레코드의 메시지 키을 역직렬화하는 클래스 지정
- value.deserializer : 레코드의 메시지 값을 역직렬화하는 클래스 지정
컨슈머 주요 옵션 (선택 옵션)
- group.id : 컨슈머 그룹 아이디를 지정 (df.null)
- subscribe() 메소드로 토픽을 구독하여 사용할 때는 이 옵션이 필수
auto.offset.reset: 컨슈머 오프셋이 없을 때 어느 오프셋부터 읽을지 선택하는 옵션 (df.latest)- enable.auto.commit : 오프셋 커밋 자동, 수동 여부 (df.true)
- max.poll.records : poll() 메서드를 통해 반환되는 레코드 개수 (df.500)
- session.timeout.ms : 컨슈머와 브로커와 연결이 끊기는 최대 시간 (df.10초)
- heartbeat.interval.ms : 하트비트 전송 시간 간격 (df.3초)
- max.poll.records.ms : poll() 호출하는 간격의 최대시간 (df. 5분)
- 레코드 처리 속도/양에 따라 조절
- isolation.level : 트랜잭션 프로듀서가 레코드를 트랜잭션 단위로 보낼 경우 사용
auto.offset.reset
- 컨슈머 그룹이 특정 파티션을 읽을 때 저장된 컨슈머 오프셋이 없는 경우 어느 오프셋 부터 읽을지 선택
- lastest : 최근 오프셋 부터 읽기 시작
- earliest : 가장 오래된 오프셋 부터 읽기 시작
멀티스레드 컨슈머
- 파티션 개수가 N개 라면 동일 컨슈머 그룹으로 묶인 컨슈머를 최대 N개 운영할 수 있다.
- N개의 스레드를 가진 1개의 프로세스 운영 또는 1개의 스레드를 가진 프로세스를 N개 운영
컨슈머랙
- 파티션의 최신 오프셋(log-end-offset)과 컨슈머 오프셋(current_offset) 간의 차이
- 컨슈머가 정상 동작하는지 여부를 확인
- 모니터링을 통해 여러 이슈 발견 가능
컨슈머랙을 모니터링하는 방법
- 카프카 명령어 사용 : kafka-consumer-groups.sh 명령 사용
- metrics() 메서드 사용
- Consumer 인스턴스의 metrics() 메서드를 활용
- records-lag-max, records-lag, records-lag-avg 지표로 확인 가능
- Consumer 정상동작할 경우만 확인 가능
- 모든 컨슈머에 모니터링 코드를 중복 작성
- 카프카 서드파티 어플리케이션의 컨슈머랙 모니터링은 불가
- Consumer 인스턴스의 metrics() 메서드를 활용
- 외부 모니터링 툴 사용
- Datadog, Confluent Control Center 와 같은 카프카 클러스터 종합 모니터링 툴 사용
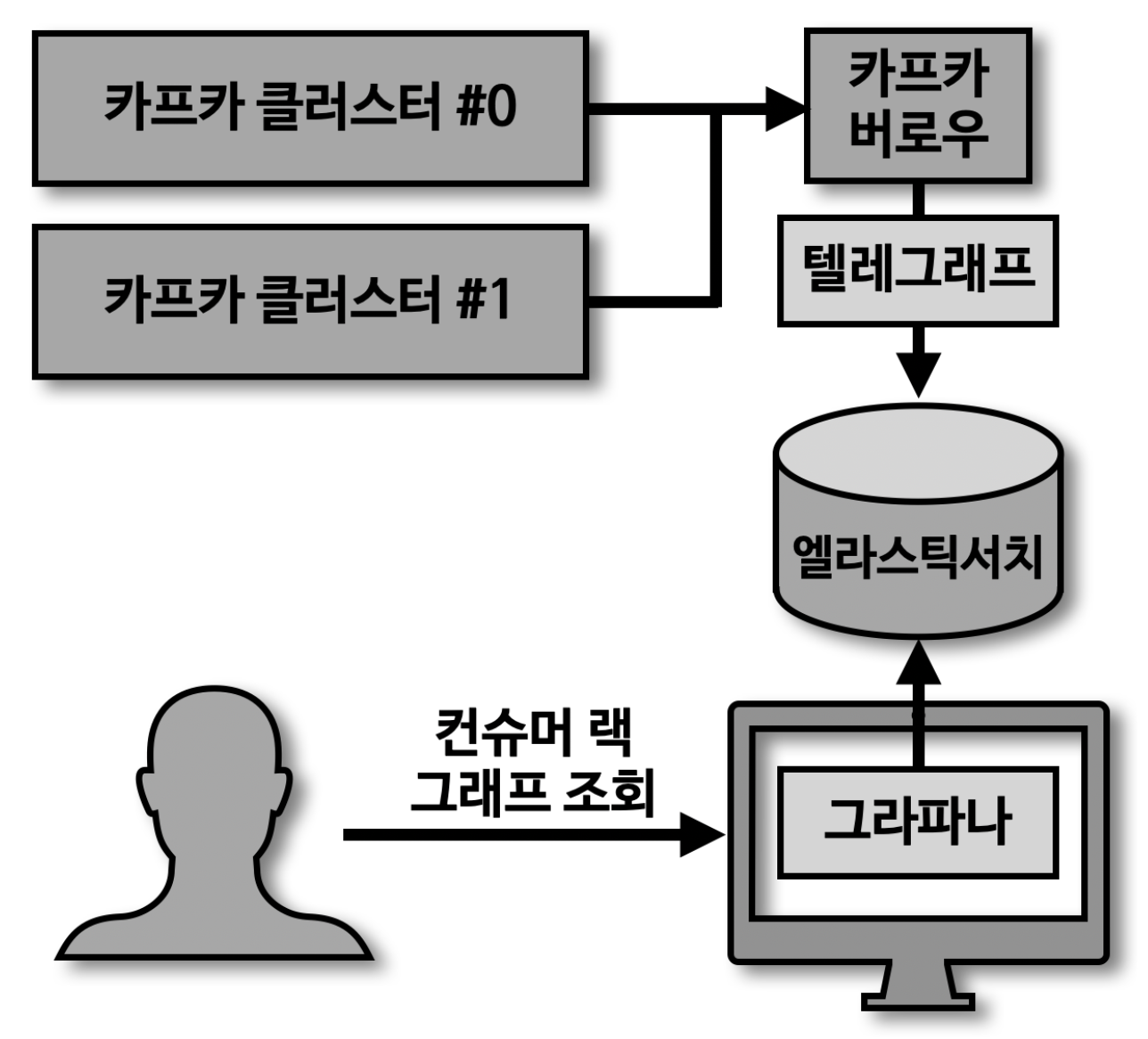
카프카 버로우
- 컨슈머랙 체크 툴로 Rest API 를 통해 확인 가능
- 다수의 카프카 클러스터를 동시에 연결 사용
- 컨슈머랙이 임계치에 도달할 때 마다 알림을 받는건 무의미
- 컨슈머랙 평가(Evaluation)
- 파티션, 컨슈머 상태 관리
- 컨슈머 처리량 이슈 - 파티선 ok, 컨슈머 warning
- 컨슈머 이슈 - 파티션 stalled, 컨슈머 error
- 컨슈머랙 모니터링 아키텍처
멱등성 프로듀서
동일한 데이터를 여러번 전송하더라도 단 한번만 저장됨- 기본 프로듀서는 at least once (중복 가능)
- Exactly once 를 위해 멱등성 프로듀서 사용
- enable.idempotence = true (
acks = all, retries = Integer.MAX_VALUE)카프카 3.x 부터는 default 로 멱등성 프로듀서 사용
- 동작방식
- 프로듀서의 PID 와 레코드의 시퀀스 넘버를 함께 전달
- 브로커에서 PID 와 SID 를 확인하여 중복을 막아준다.
- 한계
- 동일한 세션에서만 exactly once 보장
PID 변경 시 중복 메시지 발생 가능
- 브로커 부하 발생할 수 있으니 유념하여 사용
- OutOfOrderSequenceException 이 발생할 수 있다.
- 순서가 중요한 데이터 전송하는 프로듀서는 해당 익셉션 발생시 대응 방안 고려
트랜잭션 프로듀서의 동작
- 다수의 데이터를 동일 트랜잭션으로 묶음
- 전체 데이터 처리 또는 처리 안함
- 데이터를 레코드로 파티션에 저장 + 트랜잭션 레코드를 한개 더 보낸다.
트랜잭션 컨슈머의 동작
- 파티션에 저장된 트랜잭션 레코드를 보고
트랜잭션이 완료(commit) 되었음을 확인 후 데이터 가져감
트랜잭션 프로듀서의 설정
- transaction.id 를
프로듀서별로 고유한 ID 값을 사용 - initTransaction, beginTransaction, commitTransaction 순서대로 수행
트랜잭션 컨슈머의 설정
- isolation.level = read_committed 로 설정
마무리
카프카 운영 및 설치 방법 부터 프로듀서, 컨슈머 상세 내용 및 설정, 실행 방법을 살펴보는 시간이었습니다.
내용이 좀 많고, 메모한 내용을 다시 보니 기억이 잘 안나는 내용도 많네요.
역시 실무에서 사용을 하면서 여러 가지를 겪어야 진짜 내것이 되는 것 같습니다.
다음 포스팅에서는 카프카 스트림즈, 커텍트 등에 대한 내용을 포스팅 하도록 하겠습니다.
그럼 이만. 🥕👋🏼🖐🏼