
회사에서 Confluent 도입을 하며 kafka 에 대해 조금 더 이해를 해보고자 강의를 신청 했다가, 이제야 듣게 되어 내용을 정리해 두려고 합니다.
수강하는 강의는 인프런에 있는 데브원영님의 [아파치 카프카 애플리케이션 프로그래밍] 개념부터 컨슈머, 프로듀서, 커넥트, 스트림즈까지! 입니다.
카프카의 탄생
LinkedIn 에서 복잡한 아키텍처와 데이터 파이프라인 복잡도를 낮추기 위해 탄생
카프카 내부구조
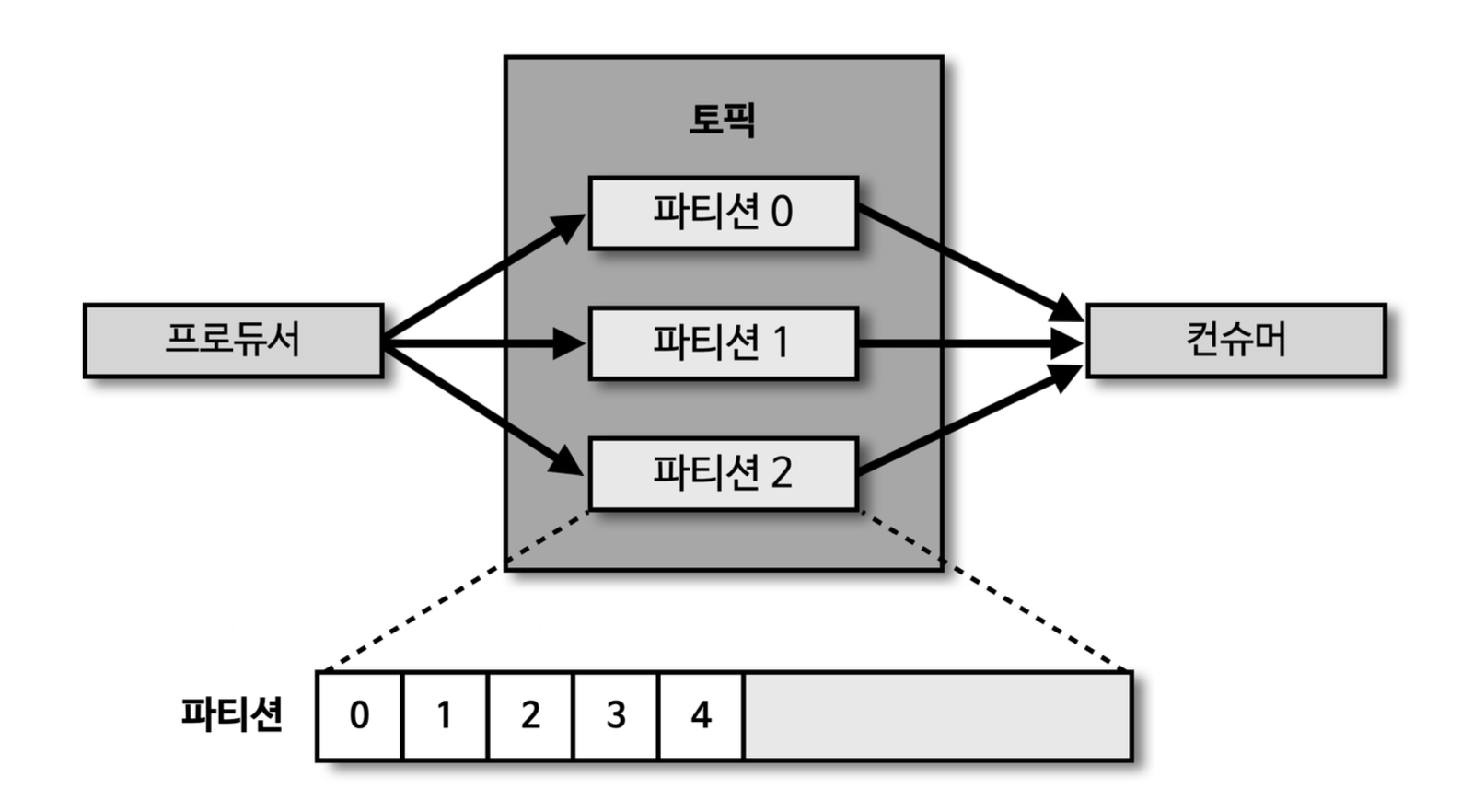
- 메세지는
파티션 중 하나에 들어간다. - 컨슈머가 메세지를 가져가도
메세지는 삭제되지 않는다.commit 을 통해 컨슈머의 메시지 순서(offset) 를 기록
데이터 파이프라인에 적합한 이유
- 높은 처리량
- 브로커와 데이터 주고 받을 때 모두 묶어서 전송 가능
- 파티션 개수만큼 컨슈머 갯수를 늘려서 동일 시간당 데이터 처리량을 늘릴 수 있다.
- 확장성
- 데이터 처리량이 많을 때 브로커를 늘려 sale-out 가능
- 데이터 처리량이 줄어들 때 sale-in 도 가능
- 데이터 처리량이 많을 때 브로커를 늘려 sale-out 가능
- 영속성
- 데이터를
파일 시스템에 저장 - 페이지 캐시 메모리 영역 사용 한번 읽은 파일 내용은 메모리에 저장 하여 처리량이 높다.
- 데이터를
- 고가용성
- 3개 이상의 브로커로 구성된 클러스터 사용
- 클러스터내 브로커간 데이터 복제(replication)를 통해 고가용성의 특징 제공
빅데이터 아키텍처의 종류와 카프카 미래
- 초기 빅데이터 플랫폼
- end to end 로 데이터를 배치로 모았다
- 유연하지 못 하고, 빠르게 전달하지 못 했다.
- end to end 로 데이터를 배치로 모았다
- 람다 아키텍처
- Batch Layer
- Speed Layer : kafka
- Serving Layer
- Batch Layer, Speed Layer 2군데 로직이 존재
- 카파 아키텍처
- Speed Layer
- Serving Layer
- Stream Data + 변화 기록 로그 = Data Snapshot
- 배치 Data
- 한정된 Data
- Stream Data
- 무한한 Data
- 스트리밍 데이터 레이크
- 거대한 용량의 데이터를 오랜 기간 저장/사용
- 자주 접근하지 않는 데이터는 별도 보관
카프카 생태계
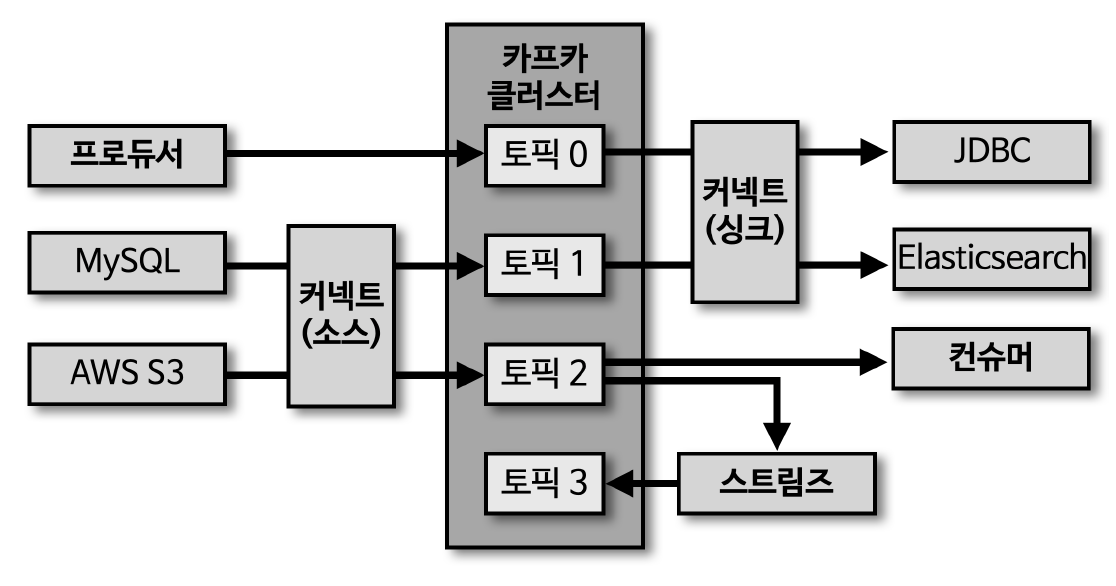
- 카프카 브로커와 클러스터
- 주키퍼 (Zookeeper)
- 카프카 2.x 는 필수, 3.x 옵션?
- 카프카 클러스터
최소한 3개의 브로커로 구성
- 카프카 브로커
- 데이터 분산 저장하는 application (브로커간 데이터 복제)
한 서버당 하나의 브로커가 일반적
- 주키퍼 (Zookeeper)
카프카 클러스터와 주키퍼
- 여러개의 카프카 클러스터가 연결된 주키퍼
- root znode 에 각 클러스터별 znode 를 생성, 클러스터 실행 시 root 가 아닌 하위 znode 로 설정
카프카 브로커의 역활
- 컨트롤러 : 클러스터의 다수의 브로커 중 한 대가 컨트롤러 역활을 한다
- 다른 브로커들의 상태를 체크 하고
이슈 발생 시 해당 브로커의 리더 파티션을 재분배 - 컨트롤러 역활을 하는 브로커에 장애 발생 시 다른 브로커가 컨트롤러 역활 담당
- 다른 브로커들의 상태를 체크 하고
- 데이터 삭제
데이터 삭제는 오직 브로커만 가능 (프로듀서, 컨슈머는 불가)로그 세그먼트 단위로 시간 또는 용량에 따라 삭제나 Compact(최신 메시지키를 제외하고 삭제)진행- 특정 데이터를 선별해서 삭제 불가
- 컨슈머 오프셋 저장
- 파티션의 어느 레코드까지 가져갔는지 확인하기 위해
오프셋을 커밋- 커밋한 오프셋은 __cousumer_offsets 토픽에 저장
- 파티션의 어느 레코드까지 가져갔는지 확인하기 위해
- 그룹 코디네이터
- 컨슈머 그룹의 상태를 체크하고
파티션을 컨슈머와 매칭되도록 분배- 기존 컨슈머가 컨슈머 그룹에서 빠지면 매칭되지 않은 파티션을 정상동작하는 컨슈머에 할당 (rebalance)
- 컨슈머 그룹의 상태를 체크하고
- 데이터 저장
- 카프카 실행시 config/server.properties 의
log.dir 옵션에 정의한 디렉토리에 데이터를 저장- 토픽 이름과 파티션 번호를 조합하여 하위 디렉토리 생성, 데이터 저장
- log 에는 메시지와 메타데이터
- index 에는 메세지의 offset 을 indexing 한 정보
- timeindex 에는 메시지에 포함된 timestamp, 메시지 키, 메시지 값 기준으로 indexing 한 정보
- 카프카 실행시 config/server.properties 의
- 로그와 세그먼트
- 로그 파일은 byte 단위(log.segment.byte, df. 1GB) + 시간주기(log.roll.ms, df. 7일) 로 새로생성
- 오프셋은 레코드의 고유한 번호
active 세그먼트 에 저장, 과거 세그먼트 저장 x브로커 삭제 대상에 포함되지 않는다.
- 로그 파일 생성시 해당 오프셋 번호가 파일 명으로 지정
active 세그먼트가 아닌 세그먼트는 retention 옵션에 따라 삭제 대상으로 지정
- 로그 파일은 byte 단위(log.segment.byte, df. 1GB) + 시간주기(log.roll.ms, df. 7일) 로 새로생성
- 세그먼트와 삭제주기
- cleanup.policy=delete
- retention.ms(minutes, hours) : 세그먼트 보유할 최대 기간 df.7일
- retention.byte : 파티션당 로그 적재 바이트 값 df.-1 (지정하지 않음)
- log.retention.check.interval.ms : 세그먼트가 삭제 영역에 들어왔는지 확인하는 간격 df.5분
- 브로커가 확인, 삭제
레코드 단위 개별 삭제 불가- 이미 적재된 데이터에 대한 수정 또한 불가능
- 프로듀싱, 컨슈밍 시 데이터 검증 하는 것이 좋다.
- cleanup.policy=compact
- 메시지 키별로 해당 메시지 키의 레코드 중 오래된 데이터를 삭제하는 정책
- 토픽 단위 설정
- 테일 영역 : 압축 정책(compact)에 의해 압축된 레코드들(클린로그)
- 중복 메시지 키가 없다.
- 헤드 영역 : 압축 정책이 되기 전 레코드들(더티로그)
- 중복 메시지 키 존재
- 메시지 키별로 해당 메시지 키의 레코드 중 오래된 데이터를 삭제하는 정책
- min.cleanable.dirty.ratio
- 데이터의 압축 시작 시점 옵션값
- 클린 레코드 갯수와 더티 레코드 갯수의 비율
- 0.5 : 두 수가 같을때
- 0.9 : 압축 효과가 좋다, 용량 효율이 낮음
- 0.1 : 최신 데이터만 유지, 빈번한 압축으로 브로커에 부담
- cleanup.policy=delete
브로커의 역활 - 복제 (Replication)
- 장애 허용 시스템 (fault tolerant system)의 원동력, 데이터 유실 방지
파티션 단위로 데이터 복제- 토픽 생성시 replicationFactor 도 설정 (미설정 시 브로커 설정값) - 리더 + 팔로워 수로 설정
- 최소값 1 (리더 파티션만 구성), 최대값 브로커 개수
- 브로커 5개 운영시 2~3으로 세팅하는게 일반적
- 복제된 파티션은 리더와 팔로워로 구성
- 프로듀서, 컨슈머가 직접 통신하는 파티션은 오직 리더 파티션
- 나머지 복제 데이터를 가지고 있는 파티션을 팔로워 파티션
- 팔로워 파티션들이 리더 파티션의 오프셋을 확인하여 차이나는 데이터를 가져와 저장
- 복제된 개수 만큼의 저장 용량 증가
- 2개 이상의 replicationFactor 를 정하는 것이 중요
- 브로커 다운시 해당 브로커의 리더 파티션 대신 팔로워 파티션 중 하나가 리더로 승급
- 데이터 종류에 맞게 토픽에 설정
- metric 데이터 rf 를 1로 설정
- 유실되면 안되는 데이터는 rf 를 3으로 설정
ISR (In-Sync-Replicas)
- 리더 파티션과 펄로워 파티션이 모두 싱크(오프셋 크기가 같다)된 상태
- unclean.leader.election.enable 설정
- ture -
유실을 감수, ISR 이 아닌 팔로워 파티션을 리더로 승급 가능 - false -
해당 브로커가 복구될 때까지 중단(토픽 중단)
- ture -
토픽과 파티션
- 토픽은 1개 이상의 파티션을 소유
- 파티션은 큐와 비슷한 구조로 레코드를 저장
- 레코드는 메시지 키와 메세지 값 등을 가짐
- 파티션에 전달 시 오프셋이 신규로 생성
- 컨슈머가 데이터를 가져가도 레코드는 삭제되지 않는다.
- 토픽 생성 시 round-robin 방식으로 브로커들에 리더 파티션들이 생성
- 특정 브로커에 통신이 집중되는 hotspot 현상을 막고, 선형 확장(linear scale out) 가능
- 특정 브로커에 파티션이 쏠림 현상
- kafka-reassign-partitions.sh 명령으로 파티션을 재분배
- 파티션과 컨슈머는 1:1,
1:N은 불가, N:1은 가능(장애 상황 등)- 컨슈머 개수를 늘림과 동시에 파티션 개수도 늘리면 처리량 증가
파티션 개수를 줄이는 것은 불가능
레코드
- 레코드는 타임스탬프, 헤더, 메세지 키, 메시지 값, 오프셋 으로 구성
- 오프셋은 브로커로 전송되면 생성
- 레코드는 수정할 수 없고, retention 기간 또는 용량에 따라서만 삭제
- 타임스탬프
- 스트림 프로세싱에서 활용하기 위한 시간을 저장하는 용도
- df. ProducerRecord 생성시간 또는 브로커 적재 시간 (logAppendTime)
- 토픽단위 설정 가능 (message.timestamp.type)
- 오프셋
- 프로두셔가 생성한 레코드에는 존재하지 않는다.
- 브로커에 적재될때 오프셋이 지정
- 컨슈머는 오프셋을 기반으로 처리 완료, 처리 해야할 데이터를 구분
- 컨슈머 커밋을 통해 기록
- 각 메세지는 파티션별 고유한 오프셋을 가진다.(컨슈머 중복처리 방지)
- 프로두셔가 생성한 레코드에는 존재하지 않는다.
- 헤더
- 키-값 데이터 추가
- 레코드의 스키마 버전이나 포맷과 같이 데이터 프로세싱에 참고할 정보를 담는다.
- 메세지 키
- 메시지 값의 분류를 하기위한 용도 (파티셔닝)
- 파티셔너에 따라 토픽의 파티션 번호가 정해짐
- 필수 값이 아니며
null 인 레코드는 파티션에 round-robin 으로 전달특정 키에 대해서는 순서보장 가능
- 메시지 값의 분류를 하기위한 용도 (파티셔닝)
- 메세지 값
- 실질적으로 처리할 데이터가 담기는 공간
- 포맷은 제네릭으로 사용자에 의해 지정
- Float, Byte[], String 등 다양한 형태 지정 가능
- 컨슈머는 미리 역직렬화 포맷을 알아야 한다.
- String 이 일반적(Json)
유지보수하기 좋은 토픽 이름 정하기
- 토픽 이름 제약 조건
- 빈문자열 토픽 이름 지원 안함
- 영어 대,소문자, 숫자, 마침표, 언더바, 하이픈 조합 생성
- 내부 로직 관리 목적 2개 토픽과 동잃한 이름으로 생성불가
- __consumer_offset, __transaction_state
- .,_ 가 동시에 사용하면 warning 메시지 발생
- 의미 있는 토픽 이름 작명 방법
- 토픽 이름 변경은 지원하지 않는다.
- 삭제 후 다시 생성
- 토픽 작명의 템플릿과 에시
- 환경.팀명.어플리케이션명.메시지타입
- 프로젝트명.서비스명.환경.이벤트명
- 환경.서비스명.Jira번호.메시지타입
- 카프카클러스터명.환경.서비스명.메시지타입
- 토픽 이름 변경은 지원하지 않는다.
클라이언트 메타데이터와 브로커 통신
- 클라이언트 메타데이터
- 통신하고자 하는
리더 파티션의 위치를 알기 윟 메타데이터를 브로커로 부터 전달받음- 카프카 클러스터와 클라이언트가 데이터 전송 전에 주고 받음
- 메타데이터 옵션
- metadata.max.age.ms : 메타데이터를 강제로 refresh 하는 간격 df. 5분
- metadata.max.idle.ms : 프로듀서가 유휴 상태일 때 메타데이터를 캐시에 유지하는 기간 df. 5분
- 클라언트 메타데이터 이슈 발생 시
- 카프카 클라이언트는 반드시 리더 파티션과 통신
- leader_not_available 익셉션 발생 : 메타데이터와 현재 파티션 상태 불일치
- 메타데이터 refresh 이슈로 발생
- 카프카 클라이언트는 반드시 리더 파티션과 통신
- 통신하고자 하는
마무리
요즘 카프카를 이용하는 서비스 들이 정말 많아지고 있는 것 같습니다. CDC 용도외에 크게 카프카를 사용하지 못 했지만, 강의를 통해 간적접으로 접해볼 수 있는 기회가 되었네요.
다음 포스팅에서 이후 내용을 다루도록 하겠습니다.
그럼 이만. 🥕👋🏼🖐🏼